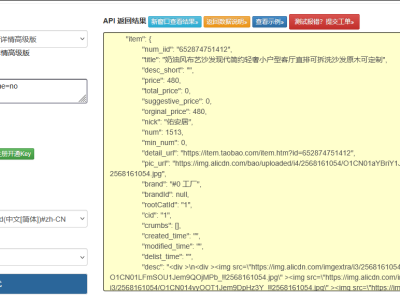
在二手电商系统开发和闲置物品交易分析场景中,某鱼平台作为国内领先的 C2C 二手交易平台,其商品数据包含丰富的个人闲置物品信息、价格趋势和交易特征。本文将将篇将详细介绍某鱼平台 API 的调用方法,包括认证机制、搜索参数配置、反爬特有的数据解析及反爬策略,并提供可直接复用的 Python 代码实现,帮助开发者合规获取二手商品数据。
一、某鱼平台接口基础信息
某鱼平台提供的开放接口主要包括商品搜索、详情查询和卖家信息获取等功能,其中/api/v2/search/items是获取二手商品列表的核心接口,特别适用于个人闲置物品的检索。
接口特点:
采用 Cookie+Token 的复合认证机制,部分接口需要登录状态
支持按物品类型、新旧程度、价格区间、地理位置等多维度筛选
包含二手商品特有的闲置原因、使用时长、瑕疵描述等字段
提供卖家信用、粉丝数、交易评价等社交化交易数据
接口端点:https://api.mouyu.com/api/v2/search/items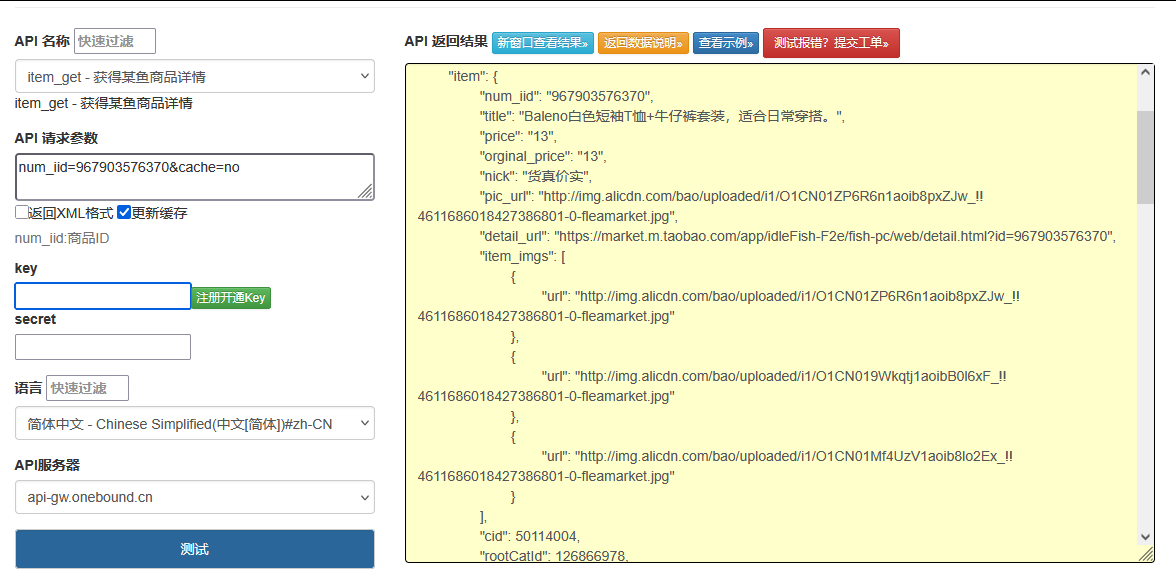
点击获取key和secret
二、认证机制与核心参数
1. 认证方式
某鱼接口采用较为严格的认证机制:
基础接口可通过公开 Cookie 访问,高级接口需要登录态 Token
登录态获取需通过手机验证码或扫码登录,生成sessionid和token
请求头需包含User-Agent、Referer和Origin等字段,模拟浏览器环境
2. 核心搜索参数
keyword:搜索关键字(物品名称、品牌等,必填)
category_id:分类 ID(3C 数码 / 家居用品 / 服装鞋帽等,可选)
item_status:物品状态(0 - 全新,1 - 几乎全新,2 - 九成新,3 - 八成新,4 - 七成新及以下)
price_min/price_max:价格区间(可选)
distance:距离范围(单位 km,1-10km,可选)
city:城市名称(按地理位置筛选,可选)
sort_type:排序方式(0 - 综合,1 - 价格低到高,2 - 价格高到低,3 - 最新发布)
page:页码(默认 1)
limit:每页条数(1-20,默认 10)
is_promotion:是否仅显示促销商品(true/false,可选)
3. 响应数据结构
total_count:总结果数
has_more:是否有更多数据
items:商品列表数组
filters:可用筛选条件
request_id:请求 ID(用于问题排查)
三、完整代码实现
以下是 Python 实现的某鱼平台商品搜索功能,包含认证处理、搜索参数构建、数据解析和反爬策略:
import requests
import time
import random
import json
from typing import Dict, List, Optional, Any, Tuple
from urllib.parse import urlencode
import logging
from fake_useragent import UserAgent
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger('mouyu_api')
class MouyuSearchAPI:
def __init__(self, cookie: str = "", proxy_pool: List[str] = None, use_login: bool = False):
"""
初始化某鱼搜索API客户端
:param cookie: 平台Cookie
:param proxy_pool: 代理IP池列表
:param use_login: 是否使用登录态(获取更多数据)
"""
self.base_url = "https://api.mouyu.com"
self.search_endpoint = "/api/v2/search/items"
self.detail_endpoint = "/api/v2/items/detail"
self.cookie = cookie
self.use_login = use_login
self.proxy_pool = proxy_pool or []
self.ua = UserAgent()
self.session = self._init_session()
self.token = self._extract_token()
def _init_session(self) -> requests.Session:
"""初始化请求会话,配置持久连接和基础头信息"""
session = requests.Session()
# 设置基础请求头
base_headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Origin": "https://m.mouyu.com",
"Referer": "https://m.mouyu.com/",
"Cookie": self.cookie
}
session.headers.update(base_headers)
return session
def _extract_token(self) -> Optional[str]:
"""从Cookie中提取token(如果有)"""
if not self.cookie:
return None
for cookie in self.cookie.split(';'):
key_value = cookie.strip().split('=')
if len(key_value) == 2 and key_value[0] == 'token':
return key_value[1]
return None
def _get_random_headers(self) -> Dict[str, str]:
"""生成随机请求头,降低反爬风险"""
headers = {
"User-Agent": self.ua.random,
"X-Requested-With": "XMLHttpRequest",
"X-Csrf-Token": self.token if self.token else "",
"Timestamp": str(int(time.time() * 1000))
}
# 登录态额外头信息
if self.use_login and self.token:
headers["Authorization"] = f"Bearer {self.token}"
return headers
def _get_proxy(self) -> Optional[Dict[str, str]]:
"""从代理池获取随机代理"""
if self.proxy_pool:
proxy = random.choice(self.proxy_pool)
return {"http": proxy, "https": proxy}
return None
def _add_random_delay(self, base: float = 1.0, range: float = 1.0) -> None:
"""添加随机延迟,模拟人类浏览行为"""
delay = base + random.random() * range
time.sleep(delay)
logger.debug(f"延迟 {delay:.2f} 秒")
def search_items(self,
keyword: str,
category_id: Optional[str] = None,
item_status: Optional[int] = None,
price_min: Optional[float] = None,
price_max: Optional[float] = None,
city: Optional[str] = None,
sort_type: int = 0,
page: int = 1,
limit: int = 10) -> Dict[str, Any]:
"""
搜索某鱼平台商品
:param keyword: 搜索关键字
:param category_id: 分类ID
:param item_status: 物品状态
:param price_min: 最低价格
:param price_max: 最高价格
:param city: 城市名称
:param sort_type: 排序方式
:param page: 页码
:param limit: 每页条数
:return: 搜索结果
"""
# 限制每页最大条数
limit = min(limit, 20)
# 构建查询参数
params: Dict[str, Any] = {
"keyword": keyword,
"sort_type": sort_type,
"page": page,
"limit": limit,
"version": "2.3.0"
}
# 添加可选参数
if category_id:
params["category_id"] = category_id
if item_status is not None:
params["item_status"] = item_status
if price_min is not None:
params["price_min"] = price_min
if price_max is not None:
params["price_max"] = price_max
if city:
params["city"] = city
# 准备请求配置
headers = self._get_random_headers()
proxy = self._get_proxy()
url = f"{self.base_url}{self.search_endpoint}?{urlencode(params)}"
try:
# 随机延迟,避免被识别为爬虫
self._add_random_delay()
# 发送请求
logger.info(f"搜索商品: {keyword}, 页码: {page}")
response = self.session.get(
url,
headers=headers,
proxies=proxy,
timeout=15
)
# 检查响应状态
if response.status_code == 401:
return {"success": False, "error_msg": "认证失败,请检查Cookie或登录状态"}
if response.status_code == 429:
return {"success": False, "error_msg": "请求过于频繁,已被临时限制"}
response.raise_for_status()
# 解析响应
result = response.json()
# 处理API错误
if result.get("code") != 0:
logger.error(f"API错误: {result.get('message')}")
return {
"success": False,
"error_code": result.get("code"),
"error_msg": result.get("message")
}
# 解析搜索结果
return self._parse_search_result(result.get("data", {}))
except requests.exceptions.RequestException as e:
logger.error(f"请求异常: {str(e)}")
return {
"success": False,
"error_msg": f"请求异常: {str(e)}"
}
except Exception as e:
logger.error(f"处理响应失败: {str(e)}")
return {
"success": False,
"error_msg": f"处理响应失败: {str(e)}"
}
def _parse_search_result(self, raw_data: Dict[str, Any]) -> Dict[str, Any]:
"""解析搜索结果为结构化数据"""
# 分页信息
pagination = {
"total_count": raw_data.get("total_count", 0),
"page": raw_data.get("page", 1),
"limit": raw_data.get("limit", 10),
"has_more": raw_data.get("has_more", False)
}
# 解析商品列表
items = []
for item in raw_data.get("items", []):
# 处理二手商品特有信息
used_info = {
"status": item.get("item_status"), # 新旧程度
"status_text": self._get_status_text(item.get("item_status")),
"used_time": item.get("used_time"), # 使用时长
"defect_desc": item.get("defect_desc") # 瑕疵描述
}
# 卖家信息
seller = {
"id": item.get("seller_id"),
"nickname": item.get("seller_nickname"),
"credit": item.get("seller_credit"), # 信用等级
"fans_count": item.get("seller_fans_count"), # 粉丝数
"location": item.get("seller_location") # 所在地
}
items.append({
"item_id": item.get("item_id"),
"title": item.get("title"),
"price": float(item.get("price", 0)),
"original_price": float(item.get("original_price", 0)),
"discount": round(float(item.get("price", 0)) / float(item.get("original_price", 1)) * 100, 1)
if item.get("original_price") else 0,
"category": {
"id": item.get("category_id"),
"name": item.get("category_name")
},
"used_info": used_info,
"seller": seller,
"sales_status": item.get("sales_status"), # 在售/已售
"publish_time": item.get("publish_time"), # 发布时间
"view_count": item.get("view_count"), # 浏览数
"comment_count": item.get("comment_count"), # 评论数
"images": {
"main": item.get("main_image"),
"thumbnails": item.get("thumbnail_images", [])
},
"url": f"https://m.mouyu.com/item/{item.get('item_id')}.html",
"tags": item.get("tags", [])
})
# 解析可用筛选条件
filters = self._parse_filters(raw_data.get("filters", {}))
return {
"success": True,
"pagination": pagination,
"items": items,
"filters": filters,
"request_id": raw_data.get("request_id")
}
def _get_status_text(self, status_code: Optional[int]) -> str:
"""将物品状态代码转换为文本描述"""
status_map = {
0: "全新",
1: "几乎全新",
2: "九成新",
3: "八成新",
4: "七成新及以下"
}
return status_map.get(status_code, "未知")
def _parse_filters(self, raw_filters: Dict[str, Any]) -> Dict[str, Any]:
"""解析筛选条件"""
filters = {}
# 分类筛选
if "categories" in raw_filters:
filters["categories"] = [
{"id": item.get("id"), "name": item.get("name"), "count": item.get("count")}
for item in raw_filters["categories"]
]
# 物品状态筛选
if "item_status" in raw_filters:
filters["item_status"] = [
{"code": item.get("code"), "name": item.get("name"), "count": item.get("count")}
for item in raw_filters["item_status"]
]
# 价格区间筛选
if "price_ranges" in raw_filters:
filters["price_ranges"] = raw_filters["price_ranges"]
return filters
def batch_search(self,
keyword: str,
max_pages: int = 3,
**kwargs) -> Dict[str, Any]:
"""
批量获取多页搜索结果
:param keyword: 搜索关键字
:param max_pages: 最大获取页数
:param**kwargs: 其他搜索参数
:return: 合并的搜索结果
"""
all_items = []
current_page = 1
has_more = True
while current_page <= max_pages and has_more:
# 搜索当前页
result = self.search_items(
keyword=keyword,
page=current_page,
**kwargs
)
if not result.get("success"):
return result
# 收集商品数据
all_items.extend(result.get("items", []))
# 更新分页信息
pagination = result.get("pagination", {})
has_more = pagination.get("has_more", False)
# 准备下一页
current_page += 1
return {
"success": True,
"total_items": len(all_items),
"items": all_items,
"summary": {
"total_available": pagination.get("total_count", 0),
"fetched_pages": current_page - 1
}
}
# 使用示例
if __name__ == "__main__":
# 替换为你的Cookie(可选,部分接口需要)
COOKIE = "your_cookie_here"
# 代理配置(可选)
PROXY_POOL = [
# "http://ip1:port",
# "http://ip2:port"
]
# 初始化API客户端
mouyu_api = MouyuSearchAPI(
cookie=COOKIE,
proxy_pool=PROXY_POOL,
use_login=False # 如需获取更多数据可设为True(需有效Cookie)
)
# 示例1:搜索二手手机
phone_result = mouyu_api.search_items(
keyword="iPhone 13",
category_id="1001", # 假设1001是手机分类
item_status=1, # 几乎全新
price_min=3000,
price_max=5000,
city="上海",
sort_type=1, # 价格从低到高
page=1,
limit=10
)
if phone_result["success"]:
print(f"搜索结果: 找到 {phone_result['pagination']['total_count']} 件相关商品")
if phone_result["items"]:
item = phone_result["items"][0]
print(f"标题: {item['title']}")
print(f"价格: {item['price']}元 (原价: {item['original_price']}元, {item['discount']}折)")
print(f"新旧程度: {item['used_info']['status_text']}")
print(f"卖家: {item['seller']['nickname']} ({item['seller']['location']})")
print(f"发布时间: {item['publish_time']}")
# 示例2:批量搜索笔记本电脑
# laptop_result = mouyu_api.batch_search(
# keyword="笔记本电脑",
# item_status=2, # 九成新
# max_pages=2
# )
#
# if laptop_result["success"]:
# print(f"\n批量搜索: 共获取 {laptop_result['total_items']} 件商品")
四、代码核心功能解析
1. 反爬策略实现
随机生成 User-Agent,模拟不同设备和浏览器环境
实现动态延迟机制,根据请求频率自动调整等待时间
支持代理 IP 池配置,分散请求来源,降低单 IP 被封风险
完整模拟浏览器请求头,包含 Referer、Origin 等关键字段
2. 二手商品特色处理
专门解析物品新旧程度、使用时长、瑕疵描述等二手特有信息
计算折扣比例,直观展示二手商品性价比
提取卖家信用等级、粉丝数等社交化交易数据
区分商品销售状态(在售 / 已售),辅助市场分析
3. 认证机制适配
支持匿名访问和登录态两种模式,灵活应对不同接口权限
自动从 Cookie 中提取认证 Token,简化登录流程
处理 401/429 等常见认证和限流错误,提供友好提示
4. 数据结构化与扩展
按业务维度组织数据,区分基础信息、二手特性、卖家信息等
解析可用筛选条件,便于前端构建高级筛选界面
提供批量搜索功能,自动处理分页和结果合并
五、实战注意事项
1. 接口权限与限制
匿名访问有严格的频率限制(通常每分钟不超过 10 次请求)
登录态访问需定期更新 Cookie,避免失效
部分敏感数据(如卖家联系方式)需要特殊权限
2. 反爬与合规
控制请求频率,建议单 IP 日请求不超过 1000 次
避免使用多线程 / 多进程高并发请求,模拟人类浏览速度
数据使用需遵守平台用户协议,不得用于商业竞品分析
3. 搜索策略优化
二手商品搜索建议结合新旧程度和价格区间筛选,提高精准度
按地理位置筛选时,使用城市名而非区域名,覆盖范围更广
批量获取数据时,合理设置max_pages参数,避免触发限制
4. 数据处理建议
标题中常包含新旧程度描述,可通过文本分析提取关键信息
价格波动较大,建议多次采样取平均值
对已售商品数据进行分析,可获取真实成交价格
六、功能扩展方向
开发二手商品价格评估模型,基于同类商品数据预测合理价格
构建卖家信用评估系统,结合多维度数据识别优质卖家
实现商品降价提醒功能,监控目标商品价格变化
开发瑕疵识别工具,基于描述文本自动分类商品瑕疵类型