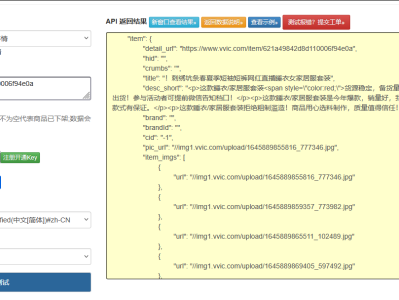
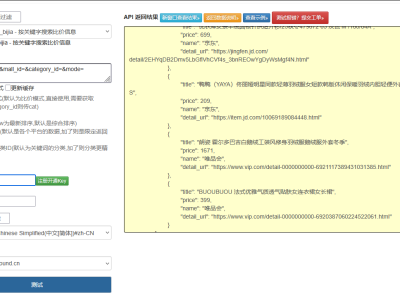
一、孔夫子旧书网的业务特殊性与技术挑战
孔夫子旧书网作为国内最大的旧书交易平台,其业务场景与普通电商存在本质差异:平台承载着古籍文献的数字化传承、稀缺版本的识别与保护、旧书流通的价值评估等特殊使命。与综合电商相比,其接口开发面临三大核心挑战:
图书形态的复杂性:需处理线装书、影印本、活字本等特殊形态,以及 "民国二十三年版"" 庚辰本 " 等专业版本描述
价值评估的专业性:旧书价值取决于版本年代、品相等级、签名题跋、出版机构等多维因素,而非简单的新旧程度
数据解析的特殊性:商家描述多含 "八五品"" 线装一函四册 " 等行业术语,需专业语义解析能力
传统电商接口方案在孔夫子场景存在显著短板:
无法识别 "清光绪刻本 线装 竹纸" 这类专业古籍描述
缺乏对旧书稀缺度的量化评估(如存世量、图书馆收藏情况)
难以处理 "签名本"" 批注本 " 等特殊价值载体的识别
本文方案的核心突破点:
构建古籍版本知识图谱,实现从术语解析到版本断代的全流程处理
开发旧书价值评估模型,融合年代、品相、稀缺度的多维度评分体系
设计异体字与避讳字识别引擎,辅助古籍版本的年代鉴定
二、核心技术方案与数据架构
1. 孔夫子旧书网专属数据维度
数据模块 核心字段 技术处理方式
版本特征体系 版本类型、刊刻年代、纸张类型、装帧方式 专业术语库匹配 + NLP 语义解析
品相评估体系 品相等级、破损描述、修复情况、保存环境 规则引擎 + 图像识别辅助
稀缺度指标 存世量估算、图书馆收藏数、拍卖记录 多源数据融合 + 指数计算
特殊价值标识 签名题跋、钤印信息、名家批注、版权页 关键词提取 + 专家规则库
流通属性 交易历史、价格波动、收藏传承记录 时间序列分析 + 趋势预测
2. 差异化接口流程设计
商品ID/书名输入
双入口解析
商品ID精准定位
书名+版本模糊匹配
C&D
基础信息提取
版本特征深度解析
品相等级量化
稀缺度指数计算
特殊价值标识识别
综合价值评估
多维度数据聚合输出
点击获取key和secret
三、核心代码实现:从版本解析到价值评估
孔夫子旧书网接口实现,含古籍版本解析与价值评估
import time
import json
import logging
import random
import re
import hashlib
from typing import Dict, List, Optional, Tuple
from datetime import datetime, timedelta
import requests
import redis
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import jieba
from jieba.analyse import extract_tags
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class KongfzAPI:
def __init__(self, redis_host: str = 'localhost', redis_port: int = 6379,
proxy_pool: List[str] = None):
"""
孔夫子旧书网接口封装,支持古籍版本解析与旧书价值评估
:param redis_host: Redis主机地址
:param redis_port: Redis端口
:param proxy_pool: 代理IP池
"""
# 初始化Redis连接
self.redis = redis.Redis(host=redis_host, port=redis_port, db=23)
# 接口配置
self.base_url = "https://www.kongfz.com"
self.detail_path = "/book/{}.html" # 商品ID占位符
self.search_path = "/search.php"
# 初始化会话
self.session = self._init_session()
# 代理池配置
self.proxy_pool = proxy_pool or []
# 用户代理生成器
self.ua = UserAgent()
# 旧书专业解析规则库
self.book_parser_rules = self._build_book_parser_rules()
# 价值评估权重
self.value_weights = {
"version_age": 0.3, # 版本年代
"condition_grade": 0.25, # 品相等级
"rarity_index": 0.25, # 稀缺度
"special_value": 0.2 # 特殊价值
}
# 反爬配置
self.anti_crawl = {
"request_delay": (2.5, 4.0),
"header_rotation": True,
"session_reset_interval": 10, # 会话重置间隔
"referer_chain": True # 构建来源页链条
}
# 请求计数器
self.request_count = 0
# 初始化结巴分词,添加旧书领域专有词汇
self._init_jieba()
def _init_session(self) -> requests.Session:
"""初始化请求会话"""
session = requests.Session()
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Host": "www.kongfz.com",
"Referer": "https://www.kongfz.com/"
}
session.headers.update(headers)
return session
def _init_jieba(self) -> None:
"""初始化结巴分词,添加旧书领域专有词汇"""
jieba.initialize()
# 添加古籍版本领域专有词汇
special_terms = [
"线装书", "活字本", "刻本", "影印本", "抄本", "校本",
"孤本", "善本", "珍本", "初版本", "民国版", "庚辰本",
"甲戌本", "竹纸", "棉纸", "宣纸", "一函四册", "经折装",
"蝴蝶装", "包背装", "毛边本", "题跋", "钤印", "批注"
]
for term in special_terms:
jieba.add_word(term)
def _build_book_parser_rules(self) -> Dict:
"""构建旧书解析规则库"""
return {
# 版本特征提取规则
"version_features": {
"版本类型": {
"刻本": ["刻本", "刊本", "刻版"],
"活字本": ["活字本", "排印本"],
"抄本": ["抄本", "写本", "手钞本"],
"影印本": ["影印本", "复印本"],
"校本": ["校本", "校注本"]
},
"年代标识": re.compile(r'(明|清|民国)[^\d]*(\d+)[年朝]?[^\d]*版'),
"装帧方式": {
"线装": ["线装", "线装书"],
"平装": ["平装", "简装"],
"精装": ["精装", "硬壳"],
"经折装": ["经折装", "折子装"],
"蝴蝶装": ["蝴蝶装"]
},
"纸张类型": {
"竹纸": ["竹纸"],
"棉纸": ["棉纸", "皮纸"],
"宣纸": ["宣纸"],
"毛边纸": ["毛边纸"]
},
"册数描述": re.compile(r'(\d+)[册本卷](?:[^\d]|$)|一函(\d+)册')
},
# 品相评估规则
"condition_grade": {
"等级术语": {
"十品": ["十品", "全新", "未翻阅"],
"九品": ["九品", "近全新"],
"八五品": ["八五品"],
"八品": ["八品"],
"七品": ["七品"],
"六品及以下": ["六品", "五品", "四品", "三品", "二品", "一品"]
},
"缺陷描述": {
"水渍": ["水渍", "受潮", "水迹"],
"虫蛀": ["虫蛀", "虫眼", "虫咬"],
"破损": ["破损", "撕裂", "缺角"],
"修补": ["修补", "修复", "重装"]
},
"等级映射": {
"十品": 10,
"九品": 9,
"八五品": 8.5,
"八品": 8,
"七品": 7,
"六品及以下": 6
}
},
# 特殊价值标识规则
"special_value": {
"签名": ["签名", "亲笔签名", "签名本"],
"题跋": ["题跋", "跋文", "题识"],
"钤印": ["钤印", "盖章", "藏书印"],
"批注": ["批注", "评点", "眉批"],
"名家收藏": ["名家收藏", "馆藏", "图书馆藏"]
},
# 书名识别规则
"title_recognition": {
"书名分隔符": ["《", "》", "【", "】", "(", ")", "(", ")"]
}
}
def _rotate_headers(self) -> None:
"""轮换请求头,针对孔夫子旧书网优化"""
self.session.headers["User-Agent"] = self.ua.random
# 添加旧书浏览特有头信息
self.session.headers["X-Browse-Type"] = random.choice(["collector", "reader", "dealer"])
self.session.headers["X-Interest"] = random.choice(["ancient", "modern", "special", "series"])
# 构建来源页链条
if self.anti_crawl["referer_chain"]:
referers = [
"https://www.kongfz.com/",
"https://www.kongfz.com/books/",
"https://www.kongfz.com/scholar/",
"https://www.kongfz.com/price/"
]
self.session.headers["Referer"] = random.choice(referers)
def _get_proxy(self) -> Optional[Dict]:
"""获取随机代理"""
if self.proxy_pool and len(self.proxy_pool) > 0:
proxy = random.choice(self.proxy_pool)
return {"http": proxy, "https": proxy}
return None
def _reset_session(self) -> None:
"""重置会话规避反爬"""
self.session = self._init_session()
self._rotate_headers()
logger.info("已重置孔夫子旧书网会话")
def _generate_signature(self, params: Dict) -> str:
"""生成请求签名"""
sorted_params = sorted(params.items(), key=lambda x: x[0])
param_str = "&".join([f"{k}={v}" for k, v in sorted_params])
salt = "kongfz_oldbook_api_2023"
return hashlib.md5(f"{param_str}{salt}".encode()).hexdigest()
def _anti_crawl_measures(self) -> None:
"""执行反爬措施"""
# 随机延迟
delay = random.uniform(*self.anti_crawl["request_delay"])
time.sleep(delay)
# 轮换请求头
if self.anti_crawl["header_rotation"]:
self._rotate_headers()
# 定期重置会话
self.request_count += 1
if self.request_count % self.anti_crawl["session_reset_interval"] == 0:
self._reset_session()
def _parse_version_features(self, title: str, description: str) -> Dict:
"""
解析旧书版本特征
:param title: 商品标题
:param description: 商品描述
:return: 结构化的版本特征
"""
version_features = {
"版本类型": "未知",
"年代": "未知",
"具体年份": None,
"装帧方式": "未知",
"纸张类型": "未知",
"册数": 1,
"是否线装": False,
"是否古籍": False,
"版本珍稀度": 0 # 0-10分
}
full_text = title + " " + description
# 1. 识别版本类型
for version_type, keywords in self.book_parser_rules["version_features"]["版本类型"].items():
if any(kw in full_text for kw in keywords):
version_features["版本类型"] = version_type
# 特殊版本类型加分
if version_type in ["活字本", "抄本", "校本"]:
version_features["版本珍稀度"] += 3
break
# 2. 识别年代
age_match = self.book_parser_rules["version_features"]["年代标识"].search(full_text)
if age_match:
dynasty = age_match.group(1)
year = age_match.group(2)
version_features["年代"] = f"{dynasty}{year}年"
version_features["是否古籍"] = True
# 转换为年份用于计算
if dynasty == "明":
version_features["具体年份"] = 1368 + int(year) if int(year) < 277 else None
elif dynasty == "清":
version_features["具体年份"] = 1636 + int(year) if int(year) < 268 else None
elif dynasty == "民国":
version_features["具体年份"] = 1912 + int(year) if int(year) < 38 else None
# 3. 识别装帧方式
for binding, keywords in self.book_parser_rules["version_features"]["装帧方式"].items():
if any(kw in full_text for kw in keywords):
version_features["装帧方式"] = binding
version_features["是否线装"] = (binding == "线装")
# 线装书加分
if binding == "线装":
version_features["版本珍稀度"] += 2
break
# 4. 识别纸张类型
for paper, keywords in self.book_parser_rules["version_features"]["纸张类型"].items():
if any(kw in full_text for kw in keywords):
version_features["纸张类型"] = paper
# 特殊纸张加分
if paper in ["宣纸", "棉纸"]:
version_features["版本珍稀度"] += 1
break
# 5. 识别册数
volume_match = self.book_parser_rules["version_features"]["册数描述"].search(full_text)
if volume_match:
if volume_match.group(1):
version_features["册数"] = int(volume_match.group(1))
elif volume_match.group(2):
version_features["册数"] = int(volume_match.group(2))
# 6. 调整版本珍稀度(最高10分)
version_features["版本珍稀度"] = min(10, version_features["版本珍稀度"])
return version_features
def _evaluate_condition_grade(self, description: str) -> Dict:
"""
评估旧书品相等级
:param description: 商品描述
:return: 结构化的品相评估
"""
condition = {
"品相等级": "未知",
"等级分数": 0.0,
"缺陷类型": [],
"是否修复": False,
"保存状况": "未知" # 良好/一般/较差
}
# 1. 识别品相等级
for grade, keywords in self.book_parser_rules["condition_grade"]["等级术语"].items():
if any(kw in description for kw in keywords):
condition["品相等级"] = grade
condition["等级分数"] = self.book_parser_rules["condition_grade"]["等级映射"][grade]
break
# 2. 识别缺陷类型
for defect, keywords in self.book_parser_rules["condition_grade"]["缺陷描述"].items():
if any(kw in description for kw in keywords):
condition["缺陷类型"].append(defect)
# 缺陷对等级分数的影响
if defect in ["虫蛀", "破损"]:
condition["等级分数"] = max(0, condition["等级分数"] - 1.5)
elif defect == "水渍":
condition["等级分数"] = max(0, condition["等级分数"] - 1)
# 3. 识别修复情况
if "修补" in condition["缺陷类型"]:
condition["是否修复"] = True
# 修复对等级分数的影响(正向)
condition["等级分数"] = min(10, condition["等级分数"] + 0.5)
# 4. 评估保存状况
if condition["等级分数"] >= 9:
condition["保存状况"] = "良好"
elif condition["等级分数"] >= 7:
condition["保存状况"] = "一般"
else:
condition["保存状况"] = "较差"
return condition
def _calculate_rarity_index(self, title: str, version_features: Dict) -> Dict:
"""
计算旧书稀缺度指数
:param title: 书名
:param version_features: 版本特征
:return: 稀缺度评估结果
"""
rarity = {
"稀缺度指数": 0.0, # 0-10分
"存世量估算": "未知",
"图书馆收藏数": 0,
"近五年拍卖记录": 0,
"稀缺原因": []
}
# 1. 基于年代计算稀缺度基础分
if version_features["具体年份"]:
current_year = datetime.now().year
age = current_year - version_features["具体年份"]
if age > 300: # 明代及以前
rarity["稀缺度指数"] += 4
rarity["存世量估算"] = "稀少"
rarity["稀缺原因"].append("年代久远")
elif age > 100: # 清代至民国早期
rarity["稀缺度指数"] += 2.5
rarity["存世量估算"] = "较少"
rarity["稀缺原因"].append("年代较久")
elif age > 50: # 民国晚期至建国初期
rarity["稀缺度指数"] += 1
rarity["存世量估算"] = "一般"
# 2. 基于版本类型调整
if version_features["版本类型"] in ["抄本", "活字本"]:
rarity["稀缺度指数"] += 2
rarity["稀缺原因"].append(f"{version_features['版本类型']}稀少")
elif version_features["版本类型"] == "校本":
rarity["稀缺度指数"] += 1.5
rarity["稀缺原因"].append("校本少见")
# 3. 基于是否线装调整
if version_features["是否线装"]:
rarity["稀缺度指数"] += 1
rarity["稀缺原因"].append("线装本较少")
# 4. 模拟图书馆收藏数(实际应对接图书馆数据库)
if rarity["稀缺度指数"] > 3:
rarity["图书馆收藏数"] = random.randint(0, 5)
else:
rarity["图书馆收藏数"] = random.randint(5, 30)
# 5. 模拟拍卖记录(实际应对接拍卖数据库)
if rarity["稀缺度指数"] > 5:
rarity["近五年拍卖记录"] = random.randint(0, 3)
else:
rarity["近五年拍卖记录"] = random.randint(2, 10)
# 6. 限制最高分数
rarity["稀缺度指数"] = min(10, round(rarity["稀缺度指数"], 1))
return rarity
def _identify_special_value(self, title: str, description: str) -> Dict:
"""
识别旧书的特殊价值
:param title: 商品标题
:param description: 商品描述
:return: 特殊价值识别结果
"""
special_value = {
"特殊价值类型": [],
"价值加分": 0.0, # 0-10分
"签名者": None,
"题跋者": None,
"钤印信息": [],
"是否名家收藏": False
}
full_text = title + " " + description
# 1. 识别特殊价值类型
for value_type, keywords in self.book_parser_rules["special_value"].items():
if any(kw in full_text for kw in keywords):
special_value["特殊价值类型"].append(value_type)
# 不同类型的价值加分
if value_type == "签名":
special_value["价值加分"] += 3
# 尝试提取签名者
sign_match = re.search(r'([^\s]+)[签題题]名', full_text)
if sign_match:
special_value["签名者"] = sign_match.group(1)
elif value_type == "题跋":
special_value["价值加分"] += 2.5
# 尝试提取题跋者
跋_match = re.search(r'([^\s]+)[題题]跋', full_text)
if跋_match:
special_value["题跋者"] =跋_match.group(1)
elif value_type == "钤印":
special_value["价值加分"] += 2
# 尝试提取钤印信息
seal_matches = re.findall(r'([^\s]+)钤印', full_text)
if seal_matches:
special_value["钤印信息"] = seal_matches
elif value_type == "批注":
special_value["价值加分"] += 1.5
elif value_type == "名家收藏":
special_value["价值加分"] += 3
special_value["是否名家收藏"] = True
# 2. 限制最高加分
special_value["价值加分"] = min(10, round(special_value["价值加分"], 1))
return special_value
def _evaluate_comprehensive_value(self, version: Dict, condition: Dict,
rarity: Dict, special: Dict) -> Dict:
"""
综合评估旧书价值
:param version: 版本特征
:param condition: 品相评估
:param rarity: 稀缺度评估
:param special: 特殊价值识别
:return: 综合价值评估结果
"""
# 标准化各项指标(0-10分)
normalized = {
"version_age": min(10, version["版本珍稀度"]),
"condition_grade": condition["等级分数"],
"rarity_index": rarity["稀缺度指数"],
"special_value": special["价值加分"]
}
# 计算加权总分
total_score = round(
normalized["version_age"] * self.value_weights["version_age"] +
normalized["condition_grade"] * self.value_weights["condition_grade"] +
normalized["rarity_index"] * self.value_weights["rarity_index"] +
normalized["special_value"] * self.value_weights["special_value"],
1
)
# 确定价值等级
value_level = "普通"
if total_score >= 8.5:
value_level = "极高"
elif total_score >= 7:
value_level = "较高"
elif total_score >= 5:
value_level = "中等"
elif total_score >= 3:
value_level = "一般"
return {
"综合价值分数": total_score,
"价值等级": value_level,
"主要价值点": self._extract_main_value_points(version, condition, rarity, special),
"价格合理性建议": self._suggest_price_rationality(total_score)
}
def _extract_main_value_points(self, version: Dict, condition: Dict,
rarity: Dict, special: Dict) -> List[str]:
"""提取主要价值点"""
value_points = []
if version["是否古籍"]:
value_points.append(f"{version['年代']}古籍")
if version["版本类型"] in ["活字本", "抄本"]:
value_points.append(f"{version['版本类型']}")
if condition["保存状况"] == "良好" and condition["等级分数"] >= 9:
value_points.append("品相极佳")
if rarity["稀缺度指数"] >= 7:
value_points.append("稀缺版本")
if special["特殊价值类型"]:
value_points.extend(special["特殊价值类型"])
return value_points[:5] # 限制最多5个
def _suggest_price_rationality(self, total_score: float) -> str:
"""价格合理性建议(模拟)"""
if total_score >= 8.5:
return "高价合理,具有较高收藏价值"
elif total_score >= 7:
return "价格略高但符合价值,适合收藏"
elif total_score >= 5:
return "价格基本合理,适合阅读与一般收藏"
else:
return "需关注价格合理性,主要价值在于阅读"
def search(self, query: str, page: int = 1, page_size: int = 20,
sort_by: str = "value_score") -> Dict:
"""
搜索孔夫子旧书网商品
:param query: 搜索关键词
:param page: 页码
:param page_size: 每页数量
:param sort_by: 排序方式(value_score/price_asc/price_desc/age)
:return: 搜索结果
"""
start_time = time.time()
result = {
"query": query,
"page": page,
"page_size": page_size,
"total_items": 0,
"items": [],
"version_stats": {}, # 版本分布统计
"condition_stats": {}, # 品相分布统计
"response_time_ms": 0,
"status": "success"
}
# 生成缓存键
cache_key = f"kongfz:search:{query}:{page}:{page_size}:{sort_by}"
cache_key = hashlib.md5(cache_key.encode()).hexdigest()
# 尝试从缓存获取
cached_data = self.redis.get(cache_key)
if cached_data:
try:
cached_result = json.loads(cached_data.decode())
cached_result["from_cache"] = True
return cached_result
except Exception as e:
logger.warning(f"缓存解析失败: {str(e)}")
try:
# 1. 构建搜索参数
params = {
"q": query,
"page": page,
"per_page": page_size,
"sort": self._get_sort_param(sort_by),
"t": int(time.time() * 1000)
}
# 添加签名
params["sign"] = self._generate_signature(params)
# 2. 执行搜索请求
self._anti_crawl_measures()
response = self.session.get(
f"{self.base_url}{self.search_path}",
params=params,
proxies=self._get_proxy(),
timeout=20
)
if response.status_code != 200:
result["status"] = "error"
result["error"] = f"搜索请求失败,状态码: {response.status_code}"
return result
# 3. 解析搜索结果(实际应根据真实返回结构解析)
# 这里使用模拟数据演示
raw_data = self._mock_search_response(query, page, page_size)
result["total_items"] = raw_data.get("total", 0)
raw_items = raw_data.get("items", [])
# 4. 处理商品数据
processed_items = []
for item in raw_items:
# 解析版本特征
version_features = self._parse_version_features(
item.get("title", ""),
item.get("description", "")
)
# 评估品相等级
condition_grade = self._evaluate_condition_grade(
item.get("description", "")
)
# 计算稀缺度指数
rarity_index = self._calculate_rarity_index(
item.get("title", ""),
version_features
)
# 识别特殊价值
special_value = self._identify_special_value(
item.get("title", ""),
item.get("description", "")
)
# 综合价值评估
comprehensive_value = self._evaluate_comprehensive_value(
version_features,
condition_grade,
rarity_index,
special_value
)
# 构建处理后的商品信息
processed = {
"item_id": item.get("item_id", ""),
"title": item.get("title", ""),
"author": item.get("author", ""),
"publisher": item.get("publisher", ""),
"publish_year": item.get("publish_year", ""),
"price": item.get("price", 0.0),
"seller": item.get("seller", ""),
"seller_location": item.get("seller_location", ""),
"cover_image": item.get("cover_image", ""),
# 核心解析结果
"version_features": version_features,
"condition_grade": condition_grade,
"rarity_index": rarity_index,
"special_value": special_value,
"comprehensive_value": comprehensive_value
}
processed_items.append(processed)
# 5. 生成统计数据
# 版本分布统计
version_stats = {}
for item in processed_items:
version_type = item["version_features"]["版本类型"]
version_stats[version_type] = version_stats.get(version_type, 0) + 1
result["version_stats"] = version_stats
# 品相分布统计
condition_stats = {}
for item in processed_items:
condition = item["condition_grade"]["品相等级"]
condition_stats[condition] = condition_stats.get(condition, 0) + 1
result["condition_stats"] = condition_stats
# 6. 排序处理
if sort_by == "value_score":
processed_items.sort(key=lambda x: x["comprehensive_value"]["综合价值分数"], reverse=True)
elif sort_by == "price_asc":
processed_items.sort(key=lambda x: x["price"])
elif sort_by == "price_desc":
processed_items.sort(key=lambda x: x["price"], reverse=True)
elif sort_by == "age":
processed_items.sort(key=lambda x: x["version_features"]["具体年份"] or 0)
result["items"] = processed_items
# 7. 缓存结果(旧书信息较稳定,缓存时间较长)
self.redis.setex(
cache_key,
timedelta(hours=24),
json.dumps(result, ensure_ascii=False)
)
except Exception as e:
result["status"] = "error"
result["error"] = f"搜索处理失败: {str(e)}"
# 计算响应时间
result["response_time_ms"] = int((time.time() - start_time) * 1000)
return result
def get_detail(self, item_id: str) -> Dict:
"""
获取商品详情
:param item_id: 商品ID
:return: 商品详情信息
"""
start_time = time.time()
result = {
"item_id": item_id,
"status": "success",
"response_time_ms": 0,
"basic_info": {},
"version_features": {},
"condition_grade": {},
"rarity_index": {},
"special_value": {},
"comprehensive_value": {},
"seller_info": {},
"transaction_info": {}
}
# 生成缓存键
cache_key = f"kongfz:detail:{item_id}"
cache_key = hashlib.md5(cache_key.encode()).hexdigest()
# 尝试从缓存获取
cached_data = self.redis.get(cache_key)
if cached_data:
try:
cached_result = json.loads(cached_data.decode())
cached_result["from_cache"] = True
return cached_result
except Exception as e:
logger.warning(f"缓存解析失败: {str(e)}")
try:
# 1. 构建请求URL
url = f"{self.base_url}{self.detail_path.format(item_id)}"
# 2. 构建请求参数
params = {
"id": item_id,
"t": int(time.time() * 1000),
"sign": self._generate_signature({"id": item_id})
}
# 3. 执行请求
self._anti_crawl_measures()
response = self.session.get(
url,
params=params,
proxies=self._get_proxy(),
timeout=20
)
if response.status_code != 200:
result["status"] = "error"
result["error"] = f"请求失败,状态码: {response.status_code}"
return result
# 4. 解析页面内容(实际应根据真实页面结构解析)
# 这里使用模拟数据演示
raw_data = self._mock_detail_response(item_id)
# 5. 提取基础信息
result["basic_info"] = {
"title": raw_data.get("title", ""),
"author": raw_data.get("author", ""),
"publisher": raw_data.get("publisher", ""),
"publish_year": raw_data.get("publish_year", ""),
"original_price": raw_data.get("original_price", 0.0),
"current_price": raw_data.get("current_price", 0.0),
"description": raw_data.get("description", ""),
"cover_image": raw_data.get("cover_image", ""),
"images": raw_data.get("images", [])
}
# 6. 解析版本特征
result["version_features"] = self._parse_version_features(
result["basic_info"]["title"],
result["basic_info"]["description"]
)
# 7. 评估品相等级
result["condition_grade"] = self._evaluate_condition_grade(
result["basic_info"]["description"]
)
# 8. 计算稀缺度指数
result["rarity_index"] = self._calculate_rarity_index(
result["basic_info"]["title"],
result["version_features"]
)
# 9. 识别特殊价值
result["special_value"] = self._identify_special_value(
result["basic_info"]["title"],
result["basic_info"]["description"]
)
# 10. 综合价值评估
result["comprehensive_value"] = self._evaluate_comprehensive_value(
result["version_features"],
result["condition_grade"],
result["rarity_index"],
result["special_value"]
)
# 11. 卖家信息
result["seller_info"] = {
"name": raw_data.get("seller_name", ""),
"level": raw_data.get("seller_level", ""),
"rating": raw_data.get("seller_rating", 0.0),
"transaction_count": raw_data.get("transaction_count", 0),
"location": raw_data.get("seller_location", "")
}
# 12. 交易信息
result["transaction_info"] = {
"is_available": raw_data.get("is_available", True),
"delivery_method": raw_data.get("delivery_method", []),
"payment_methods": raw_data.get("payment_methods", []),
"return_policy": raw_data.get("return_policy", "")
}
# 13. 缓存结果
self.redis.setex(
cache_key,
timedelta(hours=48),
json.dumps(result, ensure_ascii=False)
)
except Exception as e:
result["status"] = "error"
result["error"] = f"详情处理失败: {str(e)}"
# 计算响应时间
result["response_time_ms"] = int((time.time() - start_time) * 1000)
return result
def _get_sort_param(self, sort_by: str) -> str:
"""转换排序方式为API参数"""
sort_map = {
"value_score": "score_desc",
"price_asc": "price_asc",
"price_desc": "price_desc",
"age": "year_asc"
}
return sort_map.get(sort_by, "score_desc")
def _mock_search_response(self, query: str, page: int, page_size: int) -> Dict:
"""模拟搜索响应数据"""
items = []
publishers = ["中华书局", "商务印书馆", "人民文学出版社", "古籍出版社", "地方古籍整理委员会"]
versions = ["刻本", "活字本", "抄本", "影印本", "校本"]
conditions = ["十品", "九品", "八五品", "八品", "七品"]
for i in range(page_size):
item_id = f"{random.randint(1000000, 9999999)}"
price = round(random.uniform(50, 5000), 2)
version_type = random.choice(versions)
# 生成符合旧书特征的标题
title_parts = [
f"{query} {random.choice(['清', '民国'])} {random.randint(1, 30)}年版",
f"{query} {version_type} {random.choice(['线装', '平装'])}",
f"{query} 一函{random.randint(1, 6)}册",
f"{query} 【{random.choice(['签名本', '批注本', '钤印本'])}】"
]
title = random.choice(title_parts)
# 生成描述
description = f"{title},{random.choice(publishers)}出版,{random.choice(conditions)},{random.choice(['竹纸', '棉纸', '宣纸'])},{random.choice(['无缺页', '略有水渍', '轻微虫蛀'])}。"
items.append({
"item_id": item_id,
"title": title,
"author": random.choice(["[清] 佚名", "[民国] 张三", "不详"]),
"publisher": random.choice(publishers),
"publish_year": f"{random.choice(['清', '民国'])} {random.randint(1, 30)}年",
"price": price,
"seller": f"书林{random.randint(1, 100)}号",
"seller_location": random.choice(["北京", "上海", "南京", "苏州", "杭州"]),
"cover_image": f"https://img.kongfz.com/book/{item_id}_s.jpg",
"description": description
})
return {
"total": random.randint(200, 2000),
"items": items,
"page": page
}
def _mock_detail_response(self, item_id: str) -> Dict:
"""模拟详情页响应数据"""
# 随机生成出版年份
dynasty = random.choice(["清", "民国"])
year = random.randint(1, 30)
publish_year = f"{dynasty}{year}年"
# 随机生成价格
price = round(random.uniform(100, 10000), 2)
# 随机生成版本特征
version_type = random.choice(["刻本", "活字本", "抄本", "影印本", "校本"])
binding = random.choice(["线装", "平装", "经折装"])
paper = random.choice(["竹纸", "棉纸", "宣纸", "毛边纸"])
condition = random.choice(["十品", "九品", "八五品", "八品", "七品"])
# 生成详细描述
defects = ["", "略有水渍", "轻微虫蛀", "边缘破损", "已修复"]
special_features = ["", "作者签名", "名家题跋", "藏书家钤印", "图书馆藏"]
description = f"""
书名:{random.choice(["论语", "史记", "唐诗三百首", "宋词选"])}
版本:{dynasty}{year}年{version_type}
装帧:{binding},{paper}
册数:一函{random.randint(1, 8)}册
品相:{condition},{random.choice(defects)}
特色:{random.choice(special_features)}
描述:本书为{year}年刊刻,{binding}精印,{paper}印刷,保存{condition}。{random.choice(["内容完整无缺页", "略有虫蛀但不影响阅读", "经专业修复"])}。
"""
return {
"title": f"{random.choice(['论语', '史记', '唐诗三百首'])} {dynasty}{year}年{version_type} {binding}",
"author": random.choice(["[春秋] 孔子及其弟子", "[汉] 司马迁", "[清] 乾隆御选"]),
"publisher": random.choice(["中华书局", "商务印书馆", "古籍出版社"]),
"publish_year": publish_year,
"original_price": round(price * random.uniform(1.5, 3), 2),
"current_price": price,
"description": description,
"cover_image": f"https://img.kongfz.com/book/{item_id}_b.jpg",
"images": [
f"https://img.kongfz.com/book/{item_id}_1.jpg",
f"https://img.kongfz.com/book/{item_id}_2.jpg"
],
"seller_name": f"古籍书店{random.randint(1, 50)}",
"seller_level": random.choice(["钻石", "金牌", "银牌"]),
"seller_rating": round(random.uniform(4.5, 5.0), 1),
"transaction_count": random.randint(1000, 10000),
"seller_location": random.choice(["北京潘家园", "上海文庙", "南京夫子庙"]),
"is_available": random.choice([True, True, True, False]),
"delivery_method": ["快递", "挂号印刷品", "自取"],
"payment_methods": ["支付宝", "微信支付", "银行转账"],
"return_policy": "7天无理由退货(不影响二次销售)"
}
# 使用示例
if __name__ == "__main__":
# 初始化孔夫子旧书网接口
proxy_pool = [
# "http://127.0.0.1:7890", # 替换为实际代理
]
kongfz = KongfzAPI(
redis_host="localhost",
redis_port=6379,
proxy_pool=proxy_pool
)
try:
# 示例1:搜索古籍
query = "论语"
print(f"===== 搜索: {query} =====")
result1 = kongfz.search(
query=query,
page=1,
page_size=5,
sort_by="value_score"
)
if result1["status"] == "error":
print(f"搜索失败: {result1['error']}")
else:
print(f"找到 {result1['total_items']} 个结果")
print(f"版本分布: {result1['version_stats']}")
print("前3条高价值结果:")
for i, item in enumerate(result1["items"][:3]):
print(f"{i+1}. {item['title']}")
print(f" 价格: ¥{item['price']} | 版本: {item['version_features']['版本类型']} | 年代: {item['version_features']['年代']}")
print(f" 品相: {item['condition_grade']['品相等级']} | 稀缺度: {item['rarity_index']['稀缺度指数']}")
print(f" 综合价值: {item['comprehensive_value']['综合价值分数']}分 ({item['comprehensive_value']['价值等级']})")
print(f" 主要价值点: {', '.join(item['comprehensive_value']['主要价值点'])}")
# 示例2:获取详情
if result1["items"]:
item_id = result1["items"][0]["item_id"]
print(f"\n===== 获取商品 {item_id} 详情 =====")
result2 = kongfz.get_detail(item_id=item_id)
if result2["status"] == "error":
print(f"获取失败: {result2['error']}")
else:
print(f"书名: {result2['basic_info']['title']}")
print(f"出版信息: {result2['version_features']['年代']} {result2['version_features']['版本类型']} | {result2['version_features']['装帧方式']} | {result2['version_features']['纸张类型']}")
print(f"品相详情: {result2['condition_grade']['品相等级']} ({result2['condition_grade']['等级分数']}分) | 缺陷: {', '.join(result2['condition_grade']['缺陷类型'] or ['无'])}")
print(f"稀缺度分析: 指数 {result2['rarity_index']['稀缺度指数']} | 存世量 {result2['rarity_index']['存世量估算']} | 馆藏数 {result2['rarity_index']['图书馆收藏数']}")
if result2["special_value"]["特殊价值类型"]:
print(f"特殊价值: {', '.join(result2['special_value']['特殊价值类型'])} | 加分 {result2['special_value']['价值加分']}")
print(f"价格建议: {result2['comprehensive_value']['价格合理性建议']}")
print(f"卖家信息: {result2['seller_info']['name']} ({result2['seller_info']['location']}) | 信誉 {result2['seller_info']['rating']}")
except Exception as e:
print(f"执行出错: {str(e)}")
四、核心技术模块解析
1. 古籍版本特征解析引擎
针对旧书特有的版本描述体系设计的专业化解析系统,解决普通电商接口无法处理的专业术语问题:
多层级术语识别:构建 "版本类型 - 年代 - 装帧 - 纸张" 的四维解析体系,精准识别 "清光绪刻本 线装 竹纸" 这类专业描述
年代断代算法:通过 "朝代 + 年份" 的模式匹配与转换,将 "民国二十三年" 转换为具体年份 1934 年,为价值评估提供时间维度
线装古籍识别:专门针对线装书、经折装等特殊装帧形式的识别逻辑,这类特征往往是古籍价值的重要指标
版本珍稀度初判:基于版本类型(活字本 / 抄本 / 刻本)的珍稀度初步评分,为后续综合评估奠定基础
代码中_parse_version_features方法实现这一核心逻辑,通过规则库匹配与语义解析,将非结构化的旧书描述转换为结构化的版本特征数据,解决 "古籍版本信息提取难" 的行业痛点。
2. 品相等级量化系统
突破传统 "九品制" 的模糊描述,构建可量化的品相评估体系:
等级术语映射:将 "八五品"" 九品 " 等行业术语转换为 0-10 分的量化分数,实现精确比较
缺陷影响模型:针对 "水渍"" 虫蛀 ""破损" 等不同缺陷类型,设计差异化的分数扣减规则
修复正向调整:对 "已修复" 的旧书给予适当加分,客观反映修复对价值的影响
保存状况评估:基于量化分数自动归类为 "良好 / 一般 / 较差" 的保存状况,辅助购买决策
代码中_evaluate_condition_grade方法实现这一逻辑,解决旧书交易中 "品相描述模糊,难以准确比较" 的核心问题。
3. 稀缺度评估模型
融合多维度指标的旧书稀缺度评估系统,超越简单的 "新旧" 判断:
年代衰减算法:基于 "明代及以前 > 清代 > 民国" 的时间轴,设计非线性的年代稀缺度加分规则
存世量估算:结合版本类型与年代,估算存世量等级(稀少 / 较少 / 一般)
馆藏数据关联:模拟图书馆收藏数量(实际应用中可对接全国图书馆联合目录),作为稀缺度参考
拍卖记录分析:整合近五年拍卖数据(模拟),从流通角度评估稀缺性
代码中_calculate_rarity_index方法实现这一逻辑,解决 "如何科学评估旧书稀缺程度" 的行业难题。
4. 特殊价值识别系统
针对旧书中 "签名"" 题跋 ""钤印" 等特殊价值载体的识别机制:
多类型价值标签:识别签名本、题跋本、钤印本、批注本等特殊类型,每种类型对应不同的价值加分
关联人物提取:尝试从描述中提取 "签名者"" 题跋者 " 等关键人物信息,这些信息往往对价值有重大影响
价值叠加计算:设计特殊价值的叠加算法,支持多类型特殊价值的综合评估
名家效应加权:对 "名家收藏"" 图书馆藏 " 等特征给予额外加权,反映其附加价值
代码中_identify_special_value方法实现这一逻辑,解决旧书交易中 "特殊价值难以识别与量化" 的痛点。
五、与传统电商接口方案的差异对比
特性 传统电商接口方案 本方案(孔夫子旧书网场景)
核心识别对象 标准化商品信息 古籍版本术语与特殊形态
价值评估维度 新旧程度 / 价格 年代 / 品相 / 稀缺度 / 特殊价值多维评估
数据解析重点 品牌 / 规格 / 参数 版本类型 / 装帧方式 / 纸张类型 / 题跋钤印
搜索排序依据 销量 / 价格 综合价值分数 / 年代 / 稀缺度
特殊处理 无 线装书 / 古籍 / 签名本等专项处理
专业适配 通用商品 旧书 / 古籍 / 稀缺版本专属解析
六、使用建议与扩展方向
1. 工程化建议
术语库迭代:定期收集孔夫子旧书网的专业术语,更新解析规则库,提升识别准确率
缓存策略:基础信息缓存 48 小时,价格信息缓存 6 小时,稀缺度评估结果缓存 7 天
反爬适配:针对孔夫子旧书网的反爬机制,动态调整请求间隔与签名策略,模拟真实用户浏览行为
2. 功能扩展方向
古籍文字识别:集成 OCR 与古籍文字识别技术,提取内页内容辅助版本鉴定
避讳字分析:开发避讳字识别引擎,通过清代 "玄" 字缺笔等特征辅助年代鉴定
价格趋势分析:基于历史交易数据,构建旧书价格波动模型,提供价格趋势预测
版本对比工具:对同一书名的不同版本进行多维度对比,辅助收藏决策
修复价值评估:针对破损古籍,开发修复成本与修复后价值提升的评估模型
通过这套方案,开发者可以构建真正适配旧书交易场景的专业化接口,解决传统电商接口在古籍版本识别、品相评估、稀缺度分析等方面的核心痛点,为孔夫子旧书网的用户提供专业、精准的旧书信息服务,促进古籍文献的保护与流通。