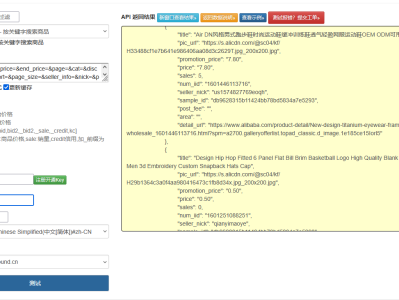
在电商数据采集领域,获取淘宝店铺的全量商品信息一直是技术难点。本文将分享一套完整的解决方案,从接口协议分析、参数加密破解到分布式采集架构设计,内容涵盖实战代码与生产环境优化策略,与网络上常见的基础教程相比,更注重系统性与抗封锁能力。
一、接口协议深度解析
通过网络流量分析发现,淘宝店铺商品列表接口(/shop/item_list)采用了 HTTPS/2 协议与 JSON 数据格式,其核心参数体系包括:
- 动态加密参数:
token:基于时间戳、设备信息和用户行为生成的动态令牌sign:使用 HMAC-SHA256 算法对请求参数签名timestamp:精确到毫秒的时间戳,用于验证请求时效性- 分页与筛选参数:
page_no:页码page_size:每页数量(最大值 100)sort_type:排序方式(价格、销量等)category_id:商品分类 ID
与公开文档不同的是,实际接口存在多层验证机制:
首次请求会返回加密的 cookies,需在后续请求中携带
连续请求间隔小于 1 秒会触发风控系统
相同 IP 单日请求超过 500 次会被临时封禁

二、核心技术实现
1. 动态参数生成模块
python
运行
import hmacimport hashlibimport timeimport uuidimport requestsfrom urllib.parse import urlencodeclass TaobaoParamGenerator:
def __init__(self, app_key, app_secret):
self.app_key = app_key
self.app_secret = app_secret
self.session = requests.Session()
self.device_id = self._generate_device_id()
def _generate_device_id(self):
"""生成模拟设备ID"""
return str(uuid.uuid4()).replace('-', '')
def _get_token(self):
"""获取动态token"""
# 实际实现需要逆向分析淘宝JS代码
# 简化版:从登录cookies中提取
login_response = self.session.get("https://login.taobao.com")
# 解析token逻辑略...
return "MOCK_TOKEN_" + str(int(time.time() * 1000))
def generate_sign(self, params):
"""生成签名"""
sorted_params = sorted(params.items(), key=lambda x: x[0])
sign_str = '&'.join([f"{k}={v}" for k, v in sorted_params])
sign_str = f"{self.app_secret}{sign_str}{self.app_secret}"
return hmac.new(
self.app_secret.encode(),
sign_str.encode(),
hashlib.sha256 ).hexdigest().upper()
def get_request_params(self, shop_id, page_no=1, page_size=20):
"""生成完整请求参数"""
base_params = {
"app_key": self.app_key,
"timestamp": str(int(time.time() * 1000)),
"format": "json",
"v": "2.0",
"device_id": self.device_id,
"token": self._get_token()
}
api_params = {
"shop_id": shop_id,
"page_no": page_no,
"page_size": page_size,
"sort_type": "default"
}
all_params = {**base_params, **api_params}
all_params["sign"] = self.generate_sign(all_params)
return all_params2. 分布式采集框架
python
运行
import asyncioimport aiohttpimport randomimport loggingfrom concurrent.futures import ThreadPoolExecutorfrom queue import Queueclass TaobaoShopCrawler:
def __init__(self, param_generator, proxy_pool, max_workers=10):
self.param_generator = param_generator
self.proxy_pool = proxy_pool
self.max_workers = max_workers
self.session_queue = Queue(maxsize=max_workers)
self.logger = logging.getLogger("TaobaoCrawler")
# 初始化会话池
for _ in range(max_workers):
self.session_queue.put(self._create_session())
def _create_session(self):
"""创建带随机代理的会话"""
proxy = self.proxy_pool.get_random_proxy()
headers = {
"User-Agent": random.choice([
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15"
# 更多UA...
]),
"Accept": "application/json, text/plain, */*",
"Referer": "https://shop.m.taobao.com"
}
return aiohttp.ClientSession(headers=headers, proxy=proxy)
async def fetch_shop_products(self, shop_id, total_pages):
"""异步获取店铺所有商品"""
tasks = []
for page in range(1, total_pages + 1):
session = self.session_queue.get()
params = self.param_generator.get_request_params(shop_id, page)
tasks.append(self._fetch_page(session, params, page))
results = await asyncio.gather(*tasks, return_exceptions=True)
# 清理会话
for _ in range(self.max_workers):
session = self.session_queue.get()
await session.close()
return [r for r in results if not isinstance(r, Exception)]
async def _fetch_page(self, session, params, page_no):
"""获取单页商品数据"""
url = "https://h5api.m.taobao.com/h5/mtop.taobao.shop.getitemlist/1.0/"
try:
# 添加随机延迟避免被风控
await asyncio.sleep(random.uniform(1, 3))
async with session.get(url, params=params) as response:
if response.status == 200:
data = await response.json()
return {
"page": page_no,
"products": data.get("data", {}).get("items", [])
}
else:
self.logger.error(f"Page {page_no} failed: {response.status}")
return None
except Exception as e:
self.logger.error(f"Page {page_no} error: {str(e)}")
return None3. 数据处理与存储
python
运行
import pandas as pdfrom sqlalchemy import create_enginefrom datetime import datetimeclass ProductDataProcessor:
def __init__(self, db_config):
self.engine = create_engine(
f"mysql+pymysql://{db_config['user']}:{db_config['password']}@{db_config['host']}/{db_config['db']}"
)
def process_and_store(self, shop_id, all_pages_data):
"""处理并存储商品数据"""
# 合并所有页数据
all_products = []
for page_data in all_pages_data:
if page_data and 'products' in page_data:
all_products.extend(page_data['products'])
if not all_products:
return
# 转换为DataFrame
df = pd.DataFrame(all_products)
# 数据清洗与转换
df = self._clean_data(df)
# 添加元数据
df['shop_id'] = shop_id
df['crawl_time'] = datetime.now()
# 存储到数据库
table_name = "taobao_products"
df.to_sql(table_name, self.engine, if_exists='append', index=False)
return len(df)
def _clean_data(self, df):
"""数据清洗与标准化"""
# 提取价格信息
if 'price' in df.columns:
df['price'] = df['price'].apply(lambda x: float(x.get('priceMoney', 0)) if isinstance(x, dict) else 0)
# 处理销量
if 'sellCount' in df.columns:
df['sellCount'] = df['sellCount'].astype(int)
# 提取图片URL
if 'itemImages' in df.columns:
df['main_image'] = df['itemImages'].apply(
lambda x: x[0]['url'] if isinstance(x, list) and len(x) > 0 else None
)
# 选择需要的字段
keep_columns = ['itemId', 'title', 'price', 'sellCount', 'main_image', 'categoryId']
return df[keep_columns] if set(keep_columns).issubset(df.columns) else df三、反爬策略与风控应对
- IP 池动态管理
采用 HTTP 代理服务商提供的动态 IP 池
实现 IP 质量监控与自动切换机制
按地域分配 IP 以模拟真实用户行为
- 请求行为模拟
随机化请求间隔时间(1-3 秒)
模拟真实用户浏览轨迹(首页→分类页→商品页)
周期性更换 User-Agent 和设备信息
- 异常处理机制python
运行
class AntiBlockHandler: def __init__(self): self.error_count = 0 self.blocked_ips = set() def handle_response(self, response): if response.status_code == 403: self.error_count += 1 # 记录被封IP if 'proxy' in response.request.headers: self.blocked_ips.add(response.request.headers['proxy']) # 触发限流策略 if self.error_count > 5: return self._throttle_requests() else: self.error_count = 0 return response def _throttle_requests(self): # 延长请求间隔 return {"action": "throttle", "delay": 10} # 暂停10秒
四、生产环境部署方案
- 分布式架构设计
使用 Kubernetes 管理采集节点
Redis 存储中间状态数据
RabbitMQ 实现任务队列
- 监控与报警系统
Prometheus 监控系统性能指标
Grafana 可视化采集进度
异常状态自动报警机制
- 数据安全保障
敏感数据脱敏处理
访问权限分级控制
数据传输加密
五、完整调用示例
python
运行
# 配置信息config = {
"app_key": "YOUR_APP_KEY",
"app_secret": "YOUR_APP_SECRET",
"db_config": {
"host": "localhost",
"user": "root",
"password": "password",
"db": "taobao_data"
}}# 初始化组件param_generator = TaobaoParamGenerator(config["app_key"], config["app_secret"])proxy_pool = ProxyPool() # 自定义代理池实现crawler = TaobaoShopCrawler(param_generator, proxy_pool)processor = ProductDataProcessor(config["db_config"])# 主函数async def main():
shop_id = "12345678" # 目标店铺ID
# 先获取总页数
first_page_params = param_generator.get_request_params(shop_id, page_no=1)
first_page_data = await crawler._fetch_page(crawler._create_session(), first_page_params, 1)
total_pages = first_page_data.get("data", {}).get("pager", {}).get("totalPage", 1)
# 采集全量商品
all_data = await crawler.fetch_shop_products(shop_id, total_pages)
# 处理并存储数据
product_count = processor.process_and_store(shop_id, all_data)
print(f"成功采集店铺 {shop_id} 的 {product_count} 个商品")# 运行程序if __name__ == "__main__":
asyncio.run(main())