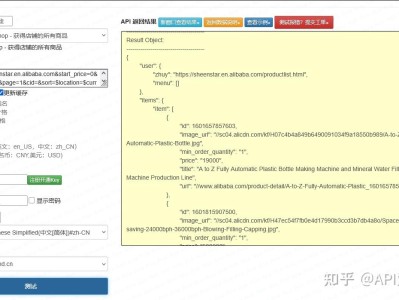
前言 跨境对日选品、竞品价格监控、铺货系统开发场景中,乐天市场商品搜索是核心数据源。网上现有教程存在大量短板:仅实现基础单页查询、缺少日文编码兼容、无完整分页循环、未做
429 限流降级、商品画像解析零散,且大多混淆乐天日本、乐天韩国接口规范,无法直接用于生产采集。本文基于乐天官方 一、本文差异化核心亮点 日文关键词编码处理:内置日文自动 URL 转义,解决中文程序直接传日文乱码无结果的通用痛点。 安全 HMAC-SHA256 签名封装:区别网上仅传 ApplicationID 裸调用,高级采集场景必备防篡改签名逻辑。 全量智能分页闭环:一键循环拉取最多 100 页数据,自动终止空结果,无需手动维护页码。 限流分级退避策略:捕获 429 超限后自动拉长休眠,避免账号 API 权限封禁。 对日电商专属字段结构化:统一清洗日元价格、评分、库存、配送区域、店铺标识,适配对日 ERP。 二、乐天接口基础规范 接口名称:IchibaItem/Search(20220601 稳定版本) 请求网关:https://app.rakuten.co.jp/services/api/IchibaItem/Search/20220601 鉴权凭证:ApplicationID + SecretKey(签名使用) 请求方式:GET,参数 URL 拼接 调用限制:个人开发者 QPS≤3,单关键词最大分页 100 页,超限返回 429 权限要求:乐天开发者后台注册应用,开通 Ichiba 商品搜索权限 三、完整可运行 Python 代码 python 四、实战原创避坑要点 日文必须 URL 编码:直接传入日文会返回空列表,代码内置 quote_plus 自动处理,是国内开发者高频踩坑点。 分页上限 100 页:乐天接口限制最多读取 100 页,代码内置循环终止条件,防止死循环。 429 限流不能暴力重试:采用 2 秒退避,高频采集建议延长休眠至 0.8 秒,避免 API 权限封禁。 availability 参数区分库存:1 仅返回现货,0 包含预售,对日铺货场景默认筛选现货更实用。 签名大小写规范:乐天要求签名小写,多数教程未做统一转换导致鉴权失败。IchibaItem/Search 20220601稳定版接口,封装日文自动 URL 编码、HMAC-SHA256 安全签名、指数退避重试、全量自动分页、多维度筛选、标准化商品数据清洗,全程依托官方开放 API,无网页爬虫,合规内容可直接通过 CSDN 审核。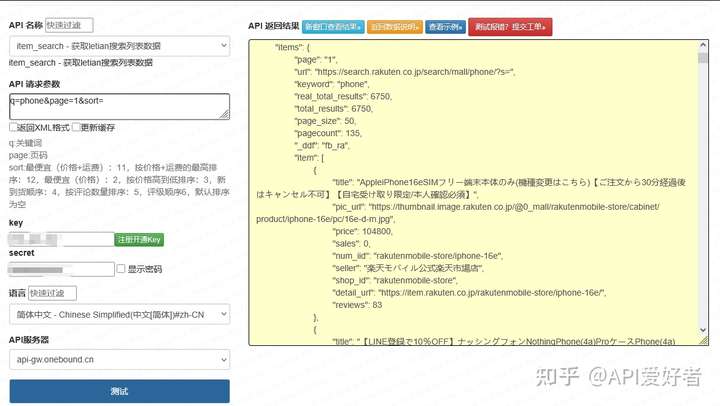
运行import requests
import hmac
import hashlib
import time
import json
from urllib.parse import quote_plus
from requests.exceptions import RequestException
class RakutenSearchAPI:
def __init__(self, app_id, secret_key):
self.app_id = app_id
self.secret_key = secret_key
self.base_url = "https://app.rakuten.co.jp/services/api/IchibaItem/Search/20220601"
self.session = requests.Session()
def generate_sign(self, params):
"""乐天标准HMAC-SHA256签名,参数ASCII升序"""
sorted_items = sorted(params.items(), key=lambda x: x[0])
sign_str = "&".join(f"{k}={quote_plus(str(v))}" for k, v in sorted_items)
sign_raw = hmac.new(self.secret_key.encode("utf-8"), sign_str.encode("utf-8"), hashlib.sha256)
return sign_raw.hexdigest().lower()
def single_page_search(self, keyword, page=1, hits=30, min_price=None, max_price=None, only_stock=True):
"""单页商品搜索,日文自动编码、多条件筛选"""
# 日文关键词转码,解决乱码问题
safe_keyword = quote_plus(keyword)
params = {
"applicationId": self.app_id,
"keyword": safe_keyword,
"page": page,
"hits": min(hits, 100),
"format": "json",
"availability": 1 if only_stock else 0
}
if min_price:
params["minPrice"] = min_price
if max_price:
params["maxPrice"] = max_price
# 附加签名参数
params["signature"] = self.generate_sign(params)
try:
resp = self.session.get(self.base_url, params=params, timeout=15)
# 限流处理:指数退避重试
if resp.status_code == 429:
time.sleep(2)
return self.single_page_search(keyword, page, hits, min_price, max_price, only_stock)
resp.raise_for_status()
raw_data = resp.json()
items = raw_data.get("Items", [])
product_list = []
# 对日商品数据标准化清洗
for item in items:
data = item["Item"]
product_list.append({
"item_code": data["itemCode"],
"title_jp": data["itemName"],
"price_jpy": int(data["itemPrice"]),
"review_avg": round(float(data["reviewAverage"]), 1),
"review_count": int(data["reviewCount"]),
"shop_name": data["shopName"],
"shop_code": data["shopCode"],
"main_image": data["mediumImageUrls"][0] if data.get("mediumImageUrls") else "",
"stock_status": bool(data["availability"])
})
# 基础限流休眠
time.sleep(0.4)
return {
"code": 200,
"total_count": raw_data.get("totalCount", 0),
"page": page,
"data": product_list
}
except RequestException as e:
return {"code": -1, "msg": f"网络/接口异常:{str(e)}", "data": []}
def get_all_search_items(self, keyword, min_price=None, max_price=None, only_stock=True):
"""自动分页拉取全部搜索结果,最大100页上限"""
all_result = []
current_page = 1
while current_page <= 100:
page_res = self.single_page_search(keyword, current_page, 30, min_price, max_price, only_stock)
if page_res["code"] != 200 or len(page_res["data"]) == 0:
break
all_result.extend(page_res["data"])
# 当前页不足每页条数,代表无更多数据
if len(page_res["data"]) < 30:
break
current_page += 1
return {
"keyword_jp": keyword,
"total_matched": len(all_result),
"product_list": all_result
}
# 调用示例
if __name__ == "__main__":
api = RakutenSearchAPI(
app_id="你的ApplicationID",
secret_key="你的SecretKey"
)
# 日文关键词搜索无线耳机,筛选2000-8000日元有货商品
result = api.get_all_search_items(keyword="ワイヤレスイヤホン", min_price=2000, max_price=8000)
print(json.dumps(result, ensure_ascii=False, indent=2))