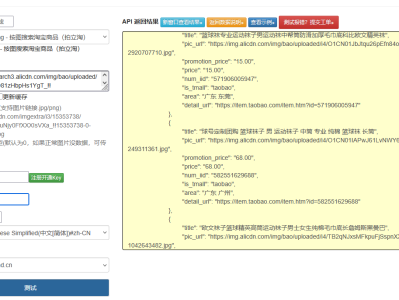
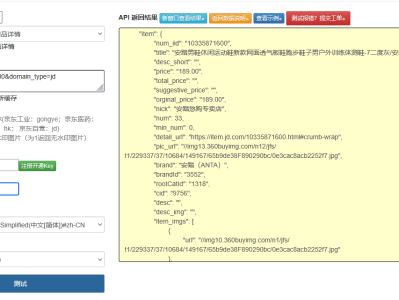
商品评论是电商平台中用户决策的重要参考依据,也是商家优化产品和服务的关键数据来源。淘宝商品评论接口作为获取这些宝贵数据的核心通道,其开发与应用一直是电商技术领域的研究热点。本文将全面解析淘宝商品评论接口的技术原理、开发流程、数据解析及扩展应用,提供完整的代码实现方案,帮助开发者快速构建稳定高效的评论数据获取系统。
一、商品评论接口技术原理与核心参数
淘宝商品评论接口基于开放平台 API 架构,通过标准化的 HTTP 请求与响应机制,实现商品评论数据的按需获取。其核心技术原理是通过商品唯一标识(如 item_id)定位商品,再通过分页和筛选参数获取指定范围的评论数据,最终以 JSON 格式返回结构化的评论信息。
核心参数解析
接口调用需关注以下关键参数,它们直接决定了数据获取的范围和质量:
参数类别 具体参数 作用说明
基础参数 item_id 商品唯一标识,必填参数,用于定位具体商品
page 页码,从 1 开始,控制分页获取
page_size 每页评论数,最大支持 20 条 / 页
筛选参数 sort 排序方式,0- 默认排序,1- 按时间倒序,2- 按有用数倒序
star 评分筛选,0- 全部,1-5- 对应星级评论
has_image 是否带图评论,0- 全部,1- 仅带图评论
认证参数 appkey 应用标识,开放平台注册获取
sign 请求签名,确保接口调用安全性
扩展参数 client_type 客户端类型,pc/mobile,影响返回数据格式
响应数据结构
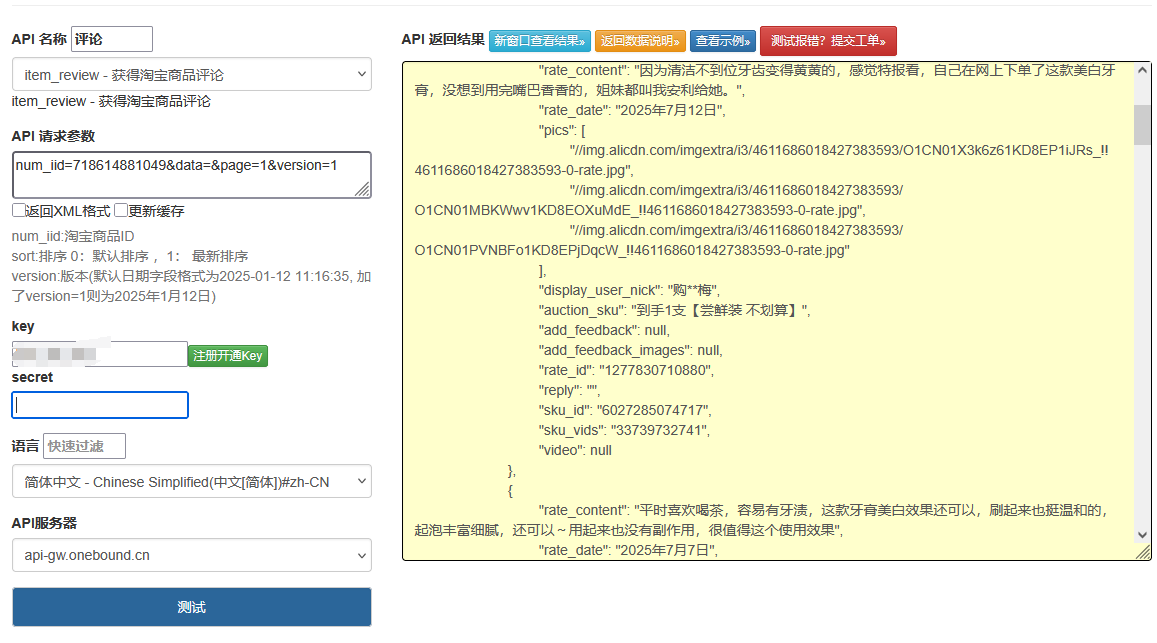
接口返回的评论数据包含丰富的结构化信息,核心数据结构如下:
json
{
"code": 0,
"msg": "success",
"data": {
"total": 1256, // 总评论数
"page": 1, // 当前页码
"page_size": 20, // 每页条数
"comments": [
{
"comment_id": "123456789", // 评论ID
"user_nick": "***阳", // 用户名(脱敏处理)
"content": "商品质量很好,物流很快", // 评论内容
"star": 5, // 评分星级
"create_time": 1689273600, // 评论时间戳
"useful": 28, // 有用数
"images": ["https://img.example.com/1.jpg"], // 评论图片
"spec": "颜色:黑色;容量:128G", // 购买规格
"reply": "感谢您的好评,祝您生活愉快" // 商家回复
}
// 更多评论...
]
}
}
点击获取key和secret
二、开发环境准备与依赖配置
开发环境要求
编程语言:Python 3.8+(推荐 3.10 版本,支持更多新特性)
开发工具:PyCharm/VS Code(带 Python 插件)
运行环境:Windows/macOS/Linux 均可,需联网环境
核心依赖库
实现评论接口调用需安装以下依赖库,通过 pip 命令快速安装:
bash
# 核心HTTP请求库
pip install requests
# 数据解析与处理库
pip install pandas
# 时间处理工具
pip install python-dateutil
# 可选:情感分析库
pip install snownlp
三、评论接口实战开发步骤
步骤 1:开放平台配置与权限申请
在调用接口前,需完成开放平台的基础配置工作:
登录淘宝开放平台注册开发者账号
创建应用,获取appkey和appsecret(密钥)
申请 "商品评论查询" 接口权限,等待审核通过
记录接口调用规范和频率限制(通常为 100 次 / 分钟)
步骤 2:签名生成工具实现
淘宝接口采用签名机制验证请求合法性,签名生成逻辑如下:
python
运行
import time
import hashlib
import urllib.parse
def generate_sign(params, app_secret):
"""
生成接口请求签名
:param params: 请求参数字典
:param app_secret: 应用密钥
:return: 签名字符串
"""
# 1. 排序参数(按参数名ASCII码升序)
sorted_params = sorted(params.items(), key=lambda x: x[0])
# 2. 拼接为key=value形式
query_string = urllib.parse.urlencode(sorted_params)
# 3. 拼接密钥并MD5加密
sign_str = f"{query_string}{app_secret}"
sign = hashlib.md5(sign_str.encode('utf-8')).hexdigest().upper()
return sign
步骤 3:评论接口调用核心实现
整合参数构建、签名生成和 HTTP 请求,实现完整的接口调用功能:
python
运行
import requests
import json
class TaobaoCommentAPI:
def __init__(self, appkey, appsecret):
self.appkey = appkey
self.appsecret = appsecret
self.api_url = "https://api.tmall.com/item/comment/search"
def get_comments(self, item_id, page=1, page_size=20, **kwargs):
"""
获取商品评论数据
:param item_id: 商品ID
:param page: 页码
:param page_size: 每页条数
:param kwargs: 其他筛选参数
:return: 评论数据字典
"""
# 1. 构建基础参数
params = {
"appkey": self.appkey,
"timestamp": str(int(time.time())),
"format": "json",
"v": "2.0",
"item_id": item_id,
"page": page,
"page_size": page_size,** kwargs
}
# 2. 生成签名
params["sign"] = generate_sign(params, self.appsecret)
try:
# 3. 发送请求
response = requests.get(
self.api_url,
params=params,
timeout=15 # 设置超时时间
)
# 4. 检查响应状态
response.raise_for_status()
# 5. 解析JSON响应
result = json.loads(response.text)
return result
except requests.exceptions.RequestException as e:
print(f"接口请求失败: {str(e)}")
return None
except json.JSONDecodeError as e:
print(f"响应数据解析失败: {str(e)}")
return None
步骤 4:评论数据解析与存储
对接口返回的原始数据进行解析,并存储为结构化格式:
python
运行
import pandas as pd
from datetime import datetime
def parse_comments(raw_data):
"""
解析评论原始数据
:param raw_data: 接口返回的原始数据
:return: 解析后的DataFrame
"""
if not raw_data or raw_data.get("code") != 0:
print(f"数据解析失败: {raw_data.get('msg', '未知错误')}")
return None
comment_list = []
comments = raw_data["data"].get("comments", [])
for comment in comments:
# 转换时间戳为可读时间
create_time = datetime.fromtimestamp(
comment.get("create_time", 0)
).strftime("%Y-%m-%d %H:%M:%S")
# 提取关键信息
comment_info = {
"comment_id": comment.get("comment_id"),
"user_nick": comment.get("user_nick"),
"content": comment.get("content", ""),
"star": comment.get("star", 0),
"create_time": create_time,
"useful": comment.get("useful", 0),
"has_image": 1 if len(comment.get("images", [])) > 0 else 0,
"spec": comment.get("spec", ""),
"has_reply": 1 if comment.get("reply") else 0
}
comment_list.append(comment_info)
# 转换为DataFrame便于后续分析
return pd.DataFrame(comment_list)
def save_comments_to_csv(df, item_id, page):
"""保存评论数据到CSV文件"""
filename = f"taobao_comments_{item_id}_page{page}.csv"
df.to_csv(filename, index=False, encoding="utf-8-sig")
print(f"已保存 {len(df)} 条评论到 {filename}")
步骤 5:完整调用示例
python
运行
if __name__ == "__main__":
# 替换为你的appkey和appsecret
APP_KEY = "your_appkey_here"
APP_SECRET = "your_appsecret_here"
# 初始化API客户端
comment_api = TaobaoCommentAPI(APP_KEY, APP_SECRET)
# 目标商品ID和分页参数
ITEM_ID = "1234567890" # 替换为实际商品ID
TOTAL_PAGES = 5 # 需要获取的总页数
# 批量获取评论
for page in range(1, TOTAL_PAGES + 1):
print(f"获取第 {page} 页评论...")
# 调用接口(筛选带图的5星好评)
raw_data = comment_api.get_comments(
item_id=ITEM_ID,
page=page,
page_size=20,
star=5, # 只获取5星评论
has_image=1, # 只获取带图评论
sort=2 # 按有用数排序
)
# 解析并保存数据
if raw_data:
comment_df = parse_comments(raw_data)
if comment_df is not None and not comment_df.empty:
save_comments_to_csv(comment_df, ITEM_ID, page)
# 控制请求频率,避免触发限流
time.sleep(2)
四、接口优化与扩展应用
性能优化策略
请求频率控制:实现智能限流机制,根据接口配额动态调整请求间隔
python
运行
def smart_sleep(remaining_quota):
"""根据剩余配额动态调整休眠时间"""
if remaining_quota < 10:
time.sleep(5) # 配额不足时延长休眠
else:
time.sleep(1) # 正常情况短休眠
断点续传机制:记录已获取的页码,支持中断后继续获取
python
运行
def load_last_page(item_id):
"""读取上次获取到的页码"""
try:
with open(f"last_page_{item_id}.txt", "r") as f:
return int(f.read().strip())
except:
return 1
def save_last_page(item_id, page):
"""保存当前获取到的页码"""
with open(f"last_page_{item_id}.txt", "w") as f:
f.write(str(page))
数据缓存策略:对热门商品评论进行本地缓存,减少重复请求
python
运行
import os
import pickle
def get_cached_comments(item_id, page):
"""获取缓存的评论数据"""
cache_file = f"cache_{item_id}_page{page}.pkl"
if os.path.exists(cache_file) and os.path.getsize(cache_file) > 0:
with open(cache_file, "rb") as f:
return pickle.load(f)
return None
def cache_comments(item_id, page, data):
"""缓存评论数据"""
cache_file = f"cache_{item_id}_page{page}.pkl"
with open(cache_file, "wb") as f:
pickle.dump(data, f)
评论情感分析扩展
利用评论数据进行情感分析,挖掘用户态度倾向:
python
运行
from snownlp import SnowNLP
def analyze_sentiment(comment_df):
"""对评论进行情感分析"""
# 添加情感分数列(0-1,越高越正面)
comment_df["sentiment"] = comment_df["content"].apply(
lambda x: SnowNLP(x).sentiments if x.strip() else 0.5
)
# 统计情感分布
positive_ratio = len(comment_df[comment_df["sentiment"] >= 0.6]) / len(comment_df)
negative_ratio = len(comment_df[comment_df["sentiment"] <= 0.4]) / len(comment_df)
print(f"正面情感占比: {positive_ratio:.2%}")
print(f"负面情感占比: {negative_ratio:.2%}")
return comment_df
# 在主流程中添加情感分析
if comment_df is not None and not comment_df.empty:
comment_df = analyze_sentiment(comment_df)
save_comments_to_csv(comment_df, ITEM_ID, page)
五、合规开发与风险规避
接口调用合规要求
权限合规:仅使用已申请通过的接口权限,不调用未授权接口
频率合规:严格遵守平台规定的调用频率限制,不进行高频请求
数据合规:
不得将评论数据用于商业售卖
对用户昵称等个人信息进行脱敏展示
保留数据来源标识,不篡改原始评论内容
常见错误处理方案
错误代码 错误原因 解决方案
400 参数错误 检查 item_id 格式和分页参数范围
401 签名错误 核对签名生成逻辑和 appsecret 有效性
403 权限不足 确认已申请对应接口权限
429 频率超限 优化请求频率控制,实现指数退避重试
500 服务器错误 记录错误日志,实现定时重试机制
异常处理完善
增强代码的健壮性,处理各类异常情况:
python
运行
def safe_get_comments(api_client, item_id, page, max_retries=3):
"""带重试机制的评论获取函数"""
retries = 0
while retries < max_retries:
try:
return api_client.get_comments(item_id, page)
except Exception as e:
retries += 1
print(f"第 {retries} 次重试获取评论...")
time.sleep(2 ** retries) # 指数退避
print(f"超过最大重试次数,获取第 {page} 页评论失败")
return None
六、总结与应用展望
本文详细讲解了淘宝商品评论接口的开发全过程,从核心参数解析、签名生成、接口调用到数据解析与存储,提供了完整的代码实现方案。通过引入性能优化策略和情感分析扩展,进一步提升了接口的实用性和数据价值。
商品评论接口的应用场景十分广泛:
电商平台可构建评论分析系统,为用户提供购买参考
商家可通过评论数据挖掘产品优缺点,优化产品设计
研究者可基于评论数据进行消费趋势分析和市场调研
随着电商技术的发展,评论接口将提供更丰富的分析维度和更实时的数据更新,开发者应持续关注平台接口文档更新,不断优化接口调用策略,充分发挥评论数据的商业价值。在开发过程中,务必坚守合规底线,实现技术价值与社会责任的统一。